如何克隆一个声音:语音克隆的初级指南
在过去的几年里,人工智能行业有了很大的进步。语音识别技术分为两部分,即对不同单词的语音识别和对实际语言的解释。根据Statista的最新报告,语音识别市场在2022年估计为120亿美元。此外,该领域的需求正在增长,所以专家说,2029年市场可能达到500亿美元--数字是惊人的。
在众多的人工智能用例中,有一些是最吸引现代企业的。首先,克隆你的声音可以为个人和专业用途提供大量具有成本效益的机会,包括改进个性化并允许本地化。我们开发了这个指南,以帮助你了解可用来用人工智能克隆你的声音的各种方法和工具,同时还强调了语音识别和克隆技术的好处和限制。
什么是人工智能语音克隆?
语音克隆是一种使用人工智能和ML来创建某人的声音的合成版本(克隆)的技术。用人工智能进行的声音克隆使用的是先前在该人的语音样本上训练过的声音复制软件。人工智能能够学习使各种声音与众不同的独特特征,使最终版本高度准确。
AI语音克隆是如何工作的?
语音克隆人工智能通过收集说话者的音频样本进行工作。虽然工作过程取决于语音克隆的类型(下面会讨论),但我们要描述的是传统的语音克隆。你拥有的目标说话人的样本越多,最终的模型就越好。样本的范围也会极大地影响最终模型,因为机器学习应该能够捕捉到不同的说话风格、情绪和口音。
你收集的样本然后被送入一个深度学习算法,开发出一个逼真的人工智能配音。这种算法可以识别目标说话人的语音模式,并学习如何复制它们。规则很简单--你给算法的数据越多,生成的语音克隆就越好。
最后一步是在声纹上训练模型,让技术开始生成新的语音,使其听起来像原来的说话者。只要算法有足够的数据,企业就可以训练生成的声音说任何话。
4个关键的语音克隆用例
一旦你克隆了你的声音,你可以通过以下方式使用它(下面只列出了几个使用情况):
- 内容创作:配音在视频(配音)和播客中非常流行。在内容创作中使用Rask AI 等人工智能语音克隆工具,可以让用户省时、省力、省钱,还能随时进行更改。
- 音频编辑:人工智能语音克隆使得在出现错误的情况下对音频记录进行必要的修改变得简单而快速。
- 增加可及性:这项技术允许用户将书面内容转换成音频格式,或创建他们自己的有声读物,为有视觉障碍的客户或那些喜欢听格式而不是文本的客户增加可及性。
- 个性化:使用语音克隆,公司或创作者可以在与客户或粉丝的互动中加入个性化的内容。这可能是个性化的信息或语音回应。
AI语音克隆功能
除了复制人们的声音,人工智能语音克隆软件还提供了许多难以忽视的神奇功能:
自然之声
你有没有在网上的许多视频中听到过那些机器人的声音?用人工智能克隆的声音与此无关。机器学习能够识别和挑选口音和情绪,所以它准确地模仿了人类的声音,听起来很自然。
多种语言可供选择
你想象一下,如果你将你的内容以数百种语言提供,你能吸引多少人?因此,当用你的母语输入你的文字时,生成的语音将是你选择的任何语言。所以它绝对不限于英语。
改变设置的能力
如果你不知道,有时生成的声音可能听起来有点不对劲。但人工智能工具允许你轻松地改变音调和速度等设置,这样你就可以创造出一个与原始声音完全匹配的声音。
如何克隆别人的声音|2种方法
1.AI语音克隆工具
简单地说,人工智能语音克隆过程中的工具是一种深度造假方法,可以分析和复制人类的声音。根据用户的经验,只需要一个你打算复制的声音样本,剩下的就由人工智能来完成。一旦复制品准备好了,你就可以直接写一段文字,人工智能应该用复制的声音来读。
目前最流行的人工智能工具有Rask AI、Murf 和 Respeecher。这些工具的功能和可用于复制语音的语言各不相同,因此需要花时间进行研究。
Rask AI 的设计涵盖了用户在配音和本地化方面的最新需求,提供多达 130 种语言(几乎是大多数同类应用程序的两倍)。你还可以免费安装Voicemod 的 Chrome 扩展或 AI 语音播报,在会议或 Discord 聊天时录制你的声音。
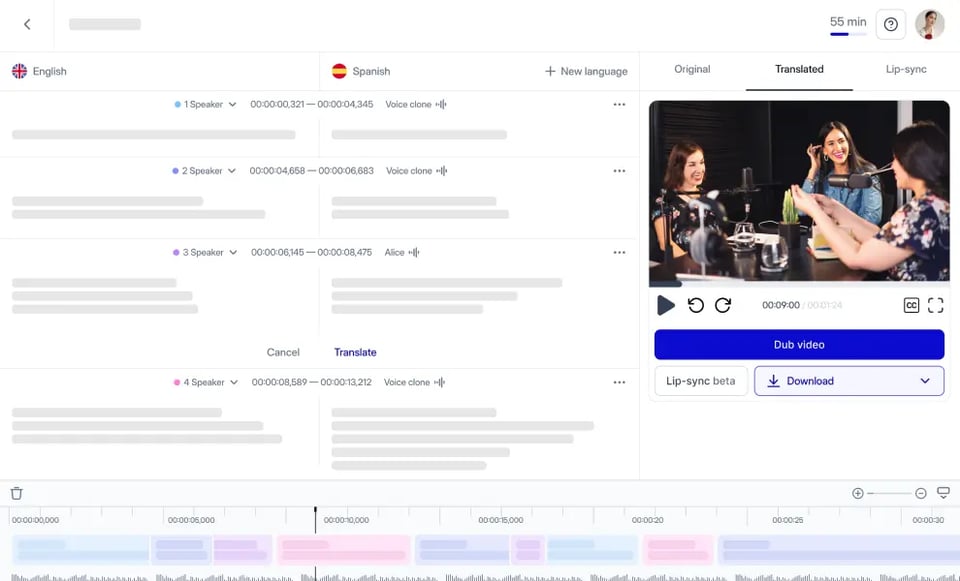
2.雇佣一个团队
经典的虽然仍然是相关的和有效的,但克隆声音的方法是雇用一个团队--无论是外包还是自由职业者的工作。确保你投入足够的时间进行市场调查,因为你要找到一个有相关经验的团队,并根据整个工作而不是文字来付费。
结束语
语音克隆技术仍处于起步阶段。但我们已经看到公司和创作者如何在不同领域使用它。由于它有这么多的好处和机会,语音克隆是与内容创作者的本地化和配音一起的领先营销工具。了解方法和原因可以帮助你更好地了解现代市场,并根据具体需求选择最适合你的方案。


.webp)

